
· 5 min read
RAG Confluence-hez: Keresés helyett válaszok
Vállalati wikik temetője helyett élő tudásbázis - Mutatom, hogyan szabadíthatod ki Confluence-edet RAG segítségével!

Bevezető
Összehasonlítom hogyan optimálisabb a confluence-ben létrehozott tartalmakból kérdezni és válaszokat összeállítani LLM (Large Language Model) és különböző közvetitő szolgáltatások használatával. Ha a RAG még nem cseng ismerősen számodra itt bővebb információt találsz róla: retrieval augmented generation.
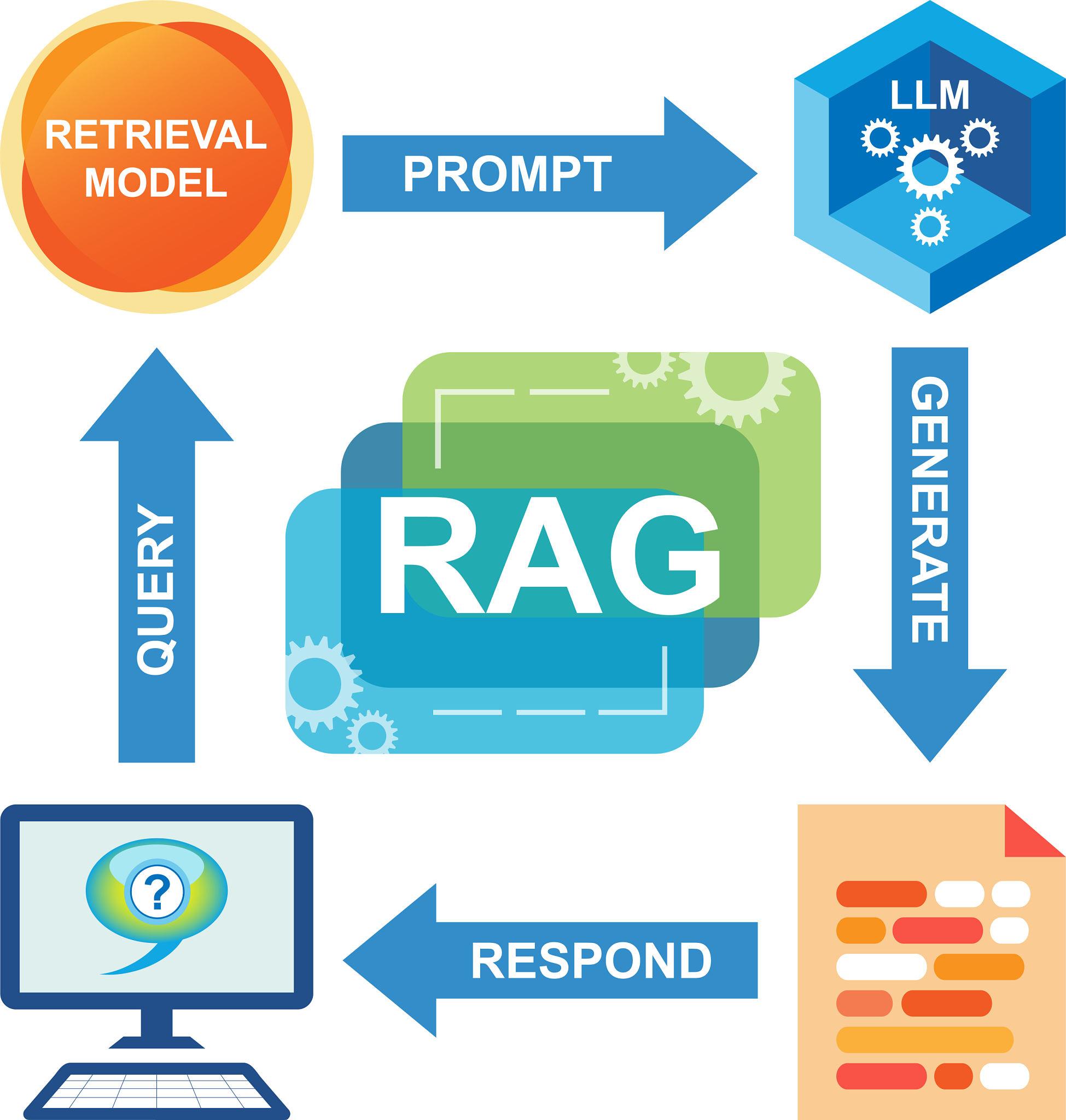
I. A gyors út: Amazon Kendra és Bedrock Knowledge Bases
Ha a cél a gyors eredmény és a „szerver nélküli” megközelítés, az AWS két natív szolgáltatást is kínál. Mindkettő képes Confluence adatforrások csatlakoztatására, de működésükben és árstruktúrájukban jelentősen eltérőek.
1. Amazon Kendra – bevált, de költséges út
Az Amazon Kendra felügyelt keresőszolgáltatás natív Confluence-összekötővel. A Kendra Confluence Cloudhoz és Serverhez egyaránt csatlakozhat, és alapértelmezetten képes értelmezni a hozzáférés-vezérlési listákat (ACL). Ennek köszönhetően nem indexel olyan dokumentumot, amelyhez az adott felhasználónak nincs jogosultsága. A konfiguráció egyszerű: az Atlassian fiókban generált API tokent vagy OAuth 2.0 hitelesítő adatokat az AWS Secrets Manager tárolja, majd az adatforrás néhány kattintással csatlakoztatható. A Kendra automatikusan indexeli a dokumentumokat és szemantikus keresést biztosít. Nem klasszikus embedding-alapú vektortárat használ, hanem saját, nem nyilvános fejlesztésű relevancia modellt.
2. Amazon Bedrock Knowledge Bases – az új generáció
A Bedrock Knowledge Bases valójában több mint egy egyszerű Confluence-összekötő. Ez az AWS válasza arra, hogy ne kelljen külön szolgáltatások között ugrálni: egy helyen kezelheted a tudásbázisodat, a keresést és a nyelvi modelleket is. Ahol a Bedrock Knowledge Bases igazán brillíroz, az az integráció. Nem kell össze barkácsolni egy Lambda-t a beágyazáshoz, nem kell vektortárat bérelni, nem kell a modellek hívogatását külön megírnod. A Bedrock tudásbázisa rendszeresen szinkronizálja a Confluence-ed tartalmát, és amikor egy felhasználó kérdez, a szolgáltatás automatikusan:
Lekéri a releváns dokumentumokat
Átadja őket a kiválasztott LLM-nek (Claude, Llama, Titan – te döntesz)
Visszaadja a választ
Mindez egyetlen API-hívás, nem pedig egy komplex kódbázis.
A Bedrock Knowledge Bases előnye, hogy szorosan integrálódik a Bedrock LLM szolgáltatásaival, így egy kérdés–válasz alkalmazás szinte „kapcsold be és működik” jelleggel felépíthető.
Összehasonlítás és korlátok
Mindkét AWS-megoldás előnye a minimális üzemeltetési overhead, bár a Kendra adatbetöltési ütemezése és felügyelete, illetve a Bedrock KB adatforrás-szinkronizációja így is némi karbantartást igényel. A Kendra árazása nagy volumen esetén valóban borsos lehet (akár havi 2000 USD+), de kisebb, 10–20 000 dokumentumos tudásbázisokhoz a GenAI Edition havi 230 USD-ért elérhető. A Bedrock Knowledge Bases árazása átláthatóbb, azonban a Confluence-összekötő jelenleg (2026 eleje) nem támogatja az ACL-ek automatikus átemelését. (A Confluence hozzáférés-vezérlési listák (ACL-ek) hierarchikusan kezelik az engedélyeket, hogy szabályozzák a felhasználók hozzáférését a területekhez és a tartalmakhoz.) Ez vállalati környezetben komoly korlát: minden felhasználó minden dokumentumot látna, függetlenül a Confluence-ben beállított jogosultságaitól.
II. A saját út: Lambda-alapú, hybrid keresős RAG pipeline
Ha a natív AWS szolgáltatások korlátai (ár, rugalmasság, jogosultságkezelés) elriasztanak, építs sajátot. Az alábbi architektúra egy éles környezetben is használható, serverless megoldás, amely Confluence-t használ adatforrásként, Pinecone-t vektor tárként.
Az adatbetöltés (Ingestion)
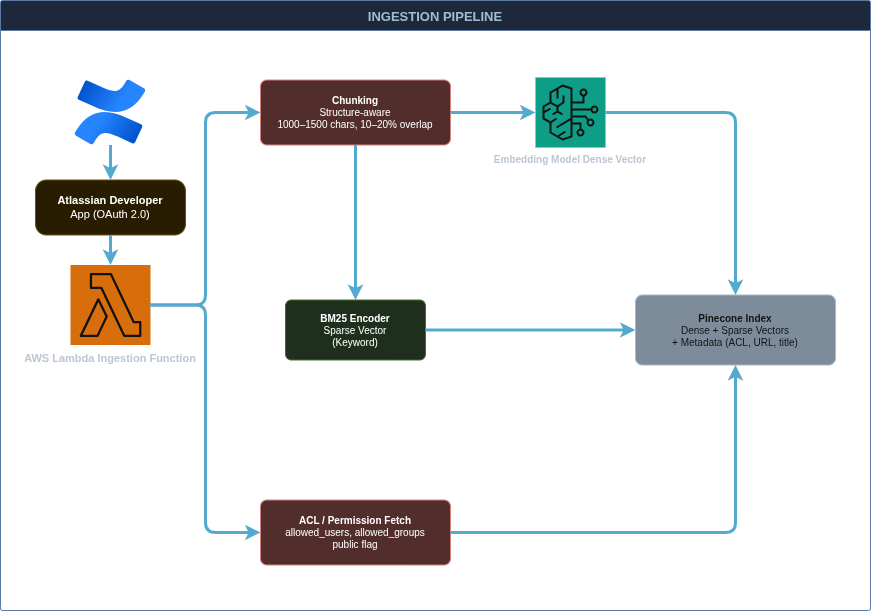
A rendszer szíve egy AWS Lambda függvény, amely szinkronizálja a Confluence tartalmát. Ehhez nem AWS natív összekötőt, hanem egy saját Atlassian Developer alkalmazást regisztrálunk az Atlassian Developer Console-ban.
Az adatbetöltés lépései
A Lambda lekéri az összes megváltozott dokumentumot Confluence felhasználói fiókkal hitelesítve.
A dokumentum törzse chunkolásra kerül.
Chunkolási stratégia Confluence tartalmakra:
A chunkolás célja, hogy a hosszú dokumentumokat szemantikailag összefüggő, önállóan is értelmezhető egységekre vágjuk. Confluence esetén érdemes struktúra tudatos chunkolást alkalmazni: a HTML-alapú oldalakban a fejezetcímek (h1, h2), táblázatok, listák és kódblokkok természetes töréspontokat jelentenek.
Egy egyszerű, mégis hatékony megközelítés a rekurzív karakter alapú chunkolás 1000–1500 karakteres darabokkal és 10–20%-os átfedéssel, ami biztosítja, hogy egy gondolatmenet ne szakadjon meg két chunk határán.
A Confluence API-ból lekérdezésre kerülnek az adott oldalra vonatkozó jogosultságok.
Minden egyes chunk metadata-ként megkapja:
- Az eredeti dokumentum URL-jét és címét
- A normalizált jogosultsági listát (allowed_users, allowed_groups, opcionálisan public flag)
- A chunk sorszámát és az oldalon belüli pozícióját
A chunk szövege alapján kétféle reprezentáció készül:
Dense vektor:
A szöveg jelentésének számsorozattá alakított reprezentációja. Az embedding modell a szavak kontextusát és szemantikai kapcsolatait is figyelembe veszi.
Sparse vektor:
Ritka, magas dimenziós vektor, ahol a dimenziók szavakat vagy tokeneket reprezentálnak. A BM25 algoritmus a lekérdezés oldalán súlyozza a szavakat gyakoriságuk alapján, így a pontos kulcsszavas találatok kiemelkedően jók.
A chunkokat a dense és sparse vektorokkal együtt töltjük fel a Pinecone indexbe.
A lekérdezés (Query) folyamata
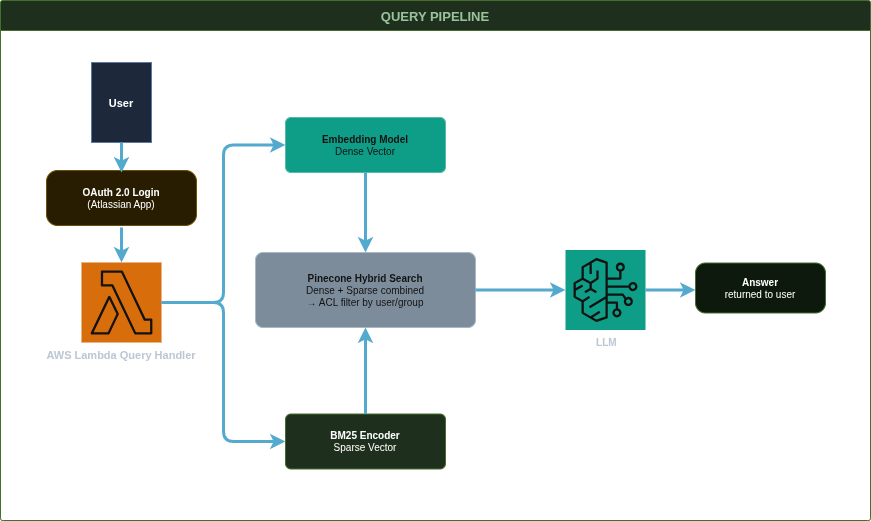
A felhasználó bejelentkezik az alkalmazásba OAuth 2.0 flow-val az Atlassian alkalmazás segítségével.
A felhasználó felteszi a kérdést: „Mi a teendő incidens esetén?”
A kérdés szövege két úton indul:
Embedding modell segítségével dense vektorrá alakítjuk
Sparse reprezentációt készítünk az indexeléskor használt módszerrel
A Pinecone hybrid search mindkét reprezentáció alapján keres, majd a találatokat a felhasználó jogosultságai szerint szűrjük.
A releváns chunkok és az eredeti kérdés együtt kerülnek továbbításra az LLM-nek, amely megfogalmazza a végső választ.
Összegzés: Miért éri meg a saját út?
A natív AWS szolgáltatások (Kendra, Bedrock) kiválóan alkalmasak prototípusok gyors felépítésére, és bizonyos esetekben hosszú távon is megállják a helyüket – különösen, ha a minimális üzemeltetés fontosabb, mint a költség vagy a jogosultságkezelés finomsága.
A Kendra 200 000 dokumentum alatt, napi 8 000 lekérdezéssel is versenyképes lehet árban a saját építésű megoldással szemben. Az ár csak nagy volumen mellett szaladhat el.
Ha azonban:
- vállalati szintű,
- finomhangolt,
- költséghatékony,
- és teljes mértékben testreszabott megoldásra van szükséged,
… a Lambda-alapú, hybrid keresős RAG rendszer a nyerő, különösen, ha:
- a jogosultságkezelés komplex (nested group-ok, space/page eltérések, public oldalak),
- vagy a havi költségkeret szűkös.
A fenti architektúra nemcsak a keresési pontosságot növeli a BM25 és a szemantikus keresés kombinációjával, hanem képes kezelni a Confluence összetett jogosultsági modelljét is.
Köszönöm, hogy elolvastad a cikket, remélem hasznosnak találtad!
Kérdésed van? Írj nekünk, és segítünk megtalálni a számodra ideális megoldásokat.
Mi az a FinOps? Ez a téma a korábbi webinárunkon is központi téma volt. Az eseményen az MVP és a növekedési fázis eltérő költséglogikáját, valamint a kapcsolódó döntési szempontokat vettük át. Ha bővebben érdekel a téma, azt itt tudod megnézni.